Things every developer absolutely, positively needs to know about database indexing - Kai Sassnowski
What is an index?
Index is an ordered representation of the indexed data. Why is an order so important? we are searching our data for the subset of the data. And searching through an ordered data is lot more efficient than searching through an unordered list. i.e. Think of binary search.
Why indexing?
It improves query performance. And is in fact one of the most common causes poor application performance.
Think of a phone book has an indexing based on last name. The phone book is ordered for exactly this type of search query.
I.e. If I give you first name, you will have to search through the whole book → bad performance.
How does indexing work? B-Tree
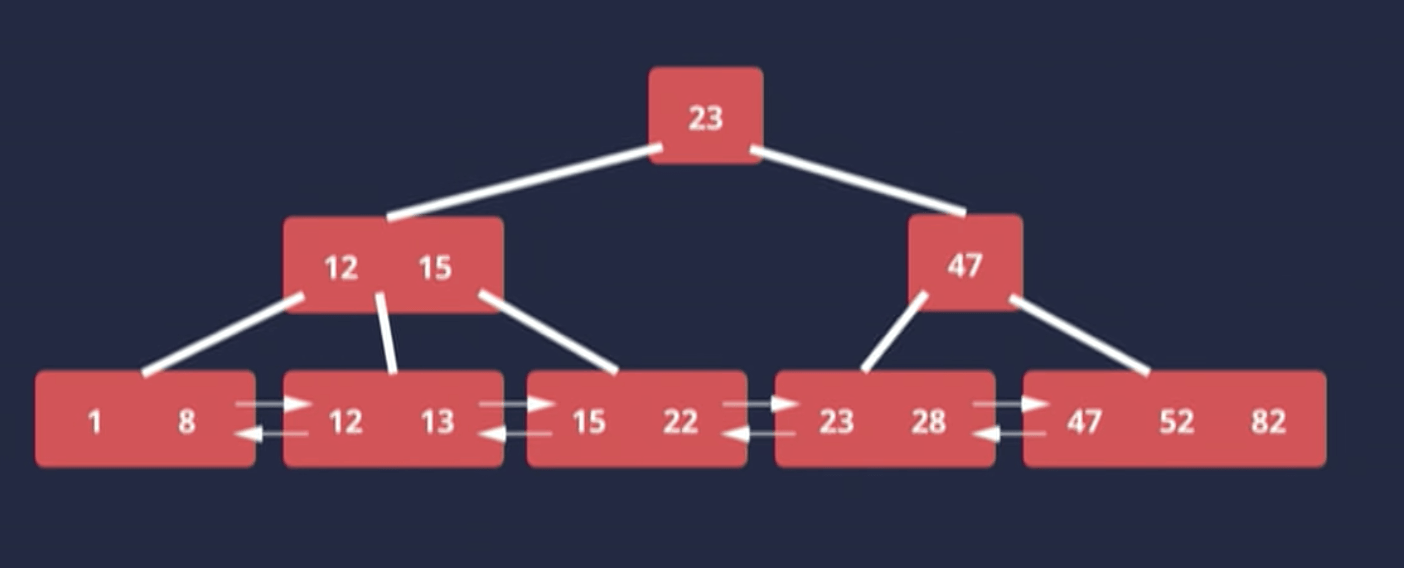
The leaf nodes are all at the same level such that it guarantees the same number of steps to find every value in the tree.
The leaves also form a doubly-linked list. Why is this important?
Turns out that we spend a lot of times down in the leaf nodes scanning through them. Without the doubly linked list, every time we arrive end of the one leaf node we would need to (1) go back up the tree and (2) find the leaf node, (3) start scanning and so on. That is not very efficient.
Having doubly linked list means that we could simply scan sequentially without having to go back up the tree again.
So what data is stored on these index?
Simple example. Let us say we put index in the name column:

We would have this as our index:
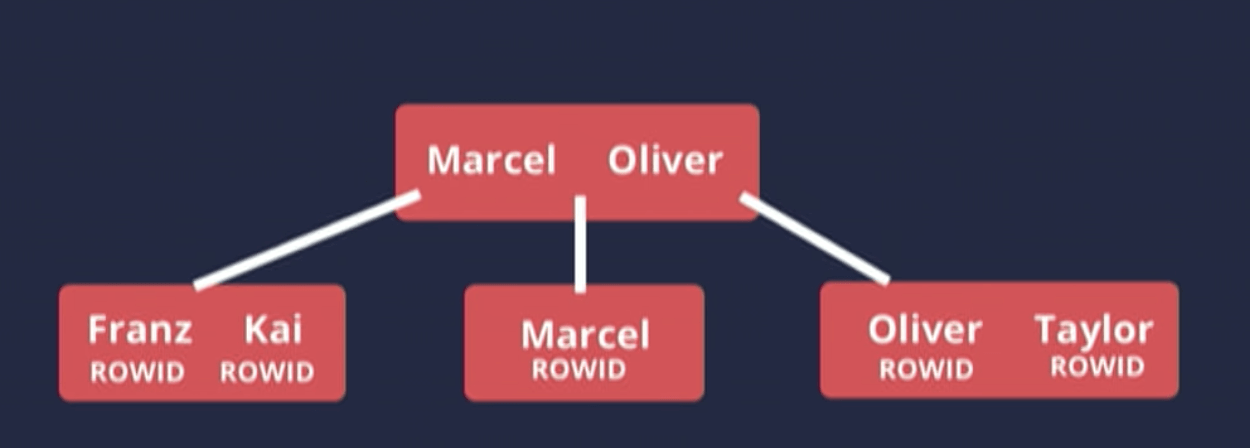
Notice that we do not have EMPLOYEE_ID is not on this index. It only contains the value of the index you put index on.
While this sounds obvious, so many developers get it wrong!
“Well, it’s like a copy of your database table, ordered by different columns” This is incorrect!
This has consequences and we will see why it is important to know what data is actually stored on the index.
How do I get back to the table if I want to know EMPLOYEE_ID of taylor?
ROWID - database internal identifier that identifies a particular row in the table. THIS IS NOT YOUR PRIMARY KEY. It is a database internal value
What are the consequences of choosing this data structure?
- Searching for a value is very, very fast! (Binary search)
- As a result, it has scales really, really well. (Logarithmic scalability) So no matter how large your n is this will keep performing.
So if indexing makes our query faster, should we put indexing in every single column?
Unfortuantely, No. There is no silver bullets - there is always only trade-offs.
Indexing improves read times. But writing slower!
Every insert / update / delete → will have to do the same in index too. Which means that the index has potential to be rebalanced → This can take a while, so if you have whole bunch of indices, your writes will be very very slow.
As a rule of thumb, you want to have as many indices as necessary but as few as possible.
Understanding the execution plan (MYSQL)
- Steps database needs to perform to execute the query.
How you get the execution plan. It is pretty uniform across database vendors.
-- Prepend explain:
EXPLAIN
SELECT *
FROM users
WHERE id = 1;
Results:
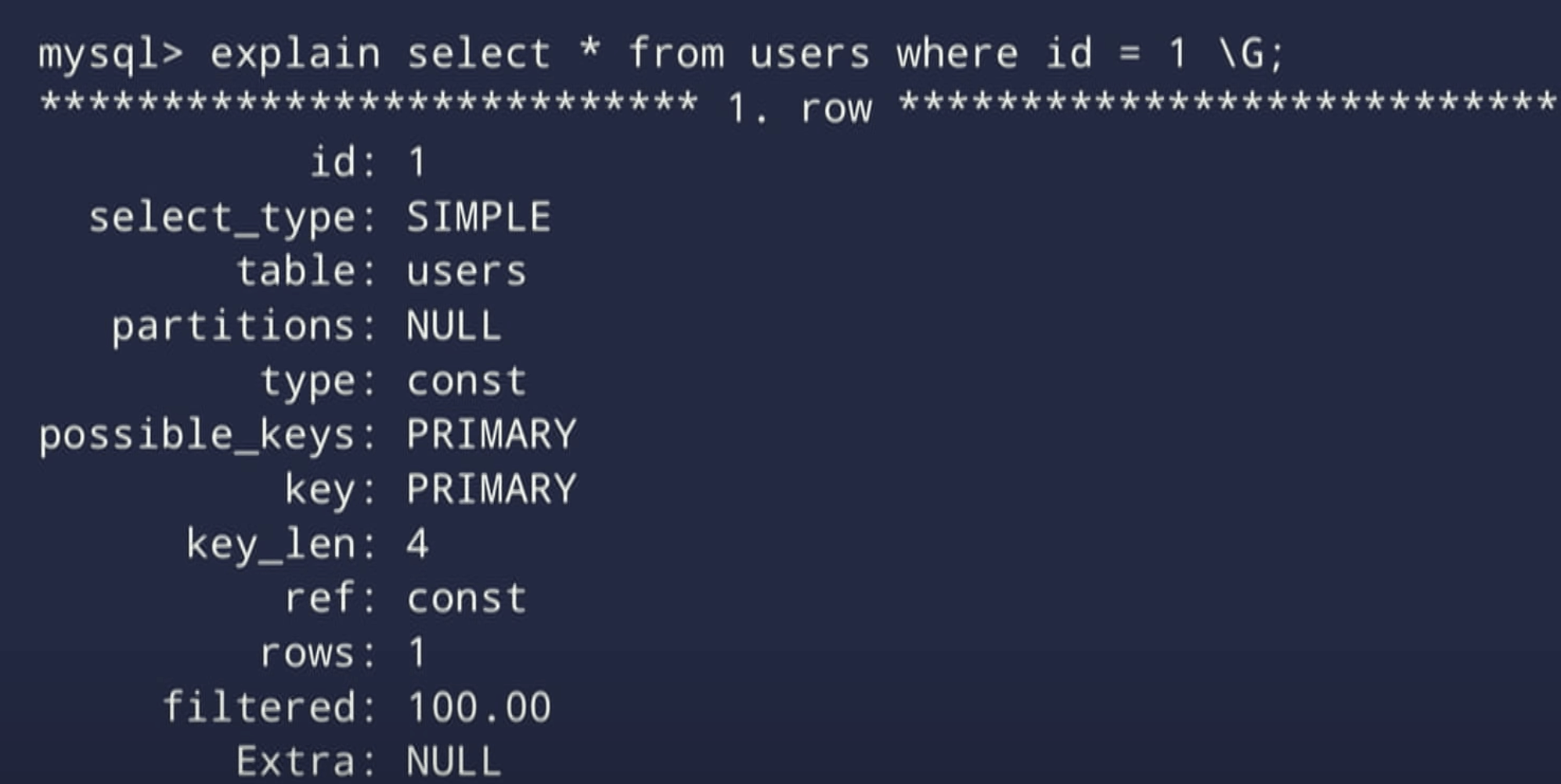
We will focus on TYPE column.
In the documentation type is referred as join type but it’s not the best name for it because there is no joins. It is a bit confusing.
Better name for it would be Access types. Because it tells us how the database is going to access our data. How it is going to use an index or not use an index to execute our query.
Let us have a look at type category:
CONST / EQ_REF
- CONST and EQ_REF are actually distinct values, but for our purpose it access the data the same way so we have grouped them here.
- Performs a B-Tree traversal to find a single value (Binary search)
- This can only be used if you can guarantee uniqueness of the result set. i.e. At most 1 result.
- Two ways to do this:
- Primary key on the column (in this example, where clause id)
- Unique constraint.
- Note: LIMIT = 1 doesn’t guarantee this. i.e. LIMIT = 1 you still fetch multiple rows and discard them afterwards.
- Two ways to do this:
- It is super fast so stop optimising any further.
REF / RANGE
- Index range scan
- Performs a B-Tree traversal to find the starting point of the range.
- Scan values from that point on by doing a linked list traversal.
- i.e. Let’s say we have query: 15 < ID < 30:
- We do B-tree traversal to find the first value > 15. And it would scan the leaf node sequentially until it hits ID == 30.
- These rows are the only rows the database even has to look at.
- It limits the total number of the rows the db has to inspect to perform the query.
INDEX
- Also known as a Full Index Scan.
- We are still using index but the rows are not limited like REF / RANGE.
- Literally start at the very first leaf node to the very last leaf node.
- Traverses through the entire index, No filtering.
ALL
- Also known as a Full Table Scan.
- Avoid at all cost!
- Does not use an index at all.
- Loads every column of every row from the table to the memory. Go through one by one, emit or discard them depending on whether they’ve fulfilled the criteria.
Common pitfalls.
1. Functions
Example: 2.5 Million rows of dummy database
id, total(cents), user_id, created_at
“Q: We want our report, we want to know the total sum of all orders that are placed in 2013.”
Try 1:
SELECT SUM(total)
FROM orders
Where YEAR(created_at) = 2013;
You see the result and it looks plausible enough so you push this and go home.
Next morning the boss says it is super slow, can you optimise this?
You can see the query takes 600ms and notice that there is only 1 column in the where clause created_at. So let’s set that as an index.
Running this you find it still takes 600ms
Let’s investigate:
EXPLAIN SELECT SUM(total)
FROM orders
Where YEAR(created_at) = 2013;
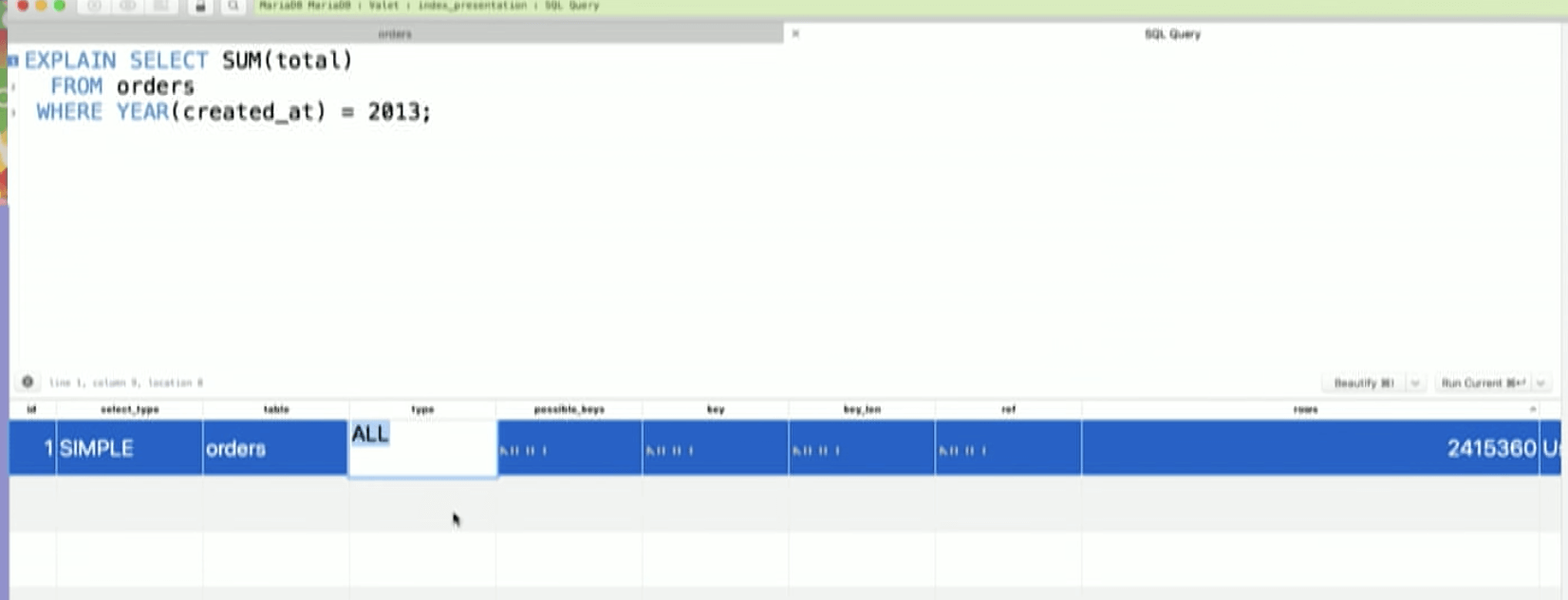
We are doing a full table scan! We will 2.5 mill rows in our memery and filter one by one!
Notice next to types there are two columns - possible_keys and key.
- Possible_keys - contains the name of indices the database set could potentially use for thㅑㄴ query
- key - index it actually uses
In this example we see NULL for both, even though we have an index. It is not being considered. So what is going on?
2. Functions
What database actually sees:
SELECT SUM(total)
FROM orders
Where YEAR(...) = 2013; --- The database column is not seen at all!
Why?
Because you cannot guarentee that the output of the database column has anything to do with the index value.
i.e. Consider a function that count string length. This number has no connection with index of string field.
So if you have a function in your where clause you cannot use an index.
Note: In Postgres there is a thing called function based indices. You can put index directly on Year(created_at) but MYSQL 8 does not have that.
Instead MYSQL has a generative columns. Generative columns add a new col to table. And in declaration the value = result of year(created_at) on that row. And since it makes a new column you can set that as an index.
But! please don’t do this. This is not how you work with dates in database! Do not make Year/Month/Days/Hours columns.
let’s say you want to look at data between 3rd April 2013 3:00am to 12th Aug 2017 6:00pm, you won’t be able to do this with year, months, hour columns.
Instead:
SELECT SUM(total)
FROM orders
Where created_at BETWEEEN '2013-01-01 00:00:00' AND '2017-12-31 23:59:59';
Now, let’s look whether this would have sped up our query?

Still ALL.
But notice now that we have orders_created_at_idx as our possible_keys.
At here, if your understanding of database isn’t so good, you maybe tempted to make further mistakes such as ‘I know better than you, I just designed and handcrafted index this database, you should really use this index.’
DO NOT TRY THIS AT WORK! (Anything that has ‘force’ is pretty bad idea)
SELECT SUM(total)
FROM orders FORCE INDEX (orders_created_at_idx)
Where created_at BETWEEEN '2013-01-01 00:00:00' AND '2017-12-31 23:59:59';

Full table scan to Range.
Rows column - it is also terribly named.
This is NOT the number of rows in the result set. It is ‘estimates’ that the DB has to look at to execute your query.
The estimate is 460k, 1/5 of 2.5mil.
So we think we’ve proved the database wrong because everything is better.
So we remove EXPLAIN and run it.
OMG, it took 4 seconds (from 600 miliseconds)
This comes back to what data is actually stored in the index.
Index only has created_at but query says SUM(total). we are also referencing total.
The total column is not on the index.
So.. out of 466k estimated rows:
(1) It will have to take ROWID,
(2) Go back to the table,
(3) Fetch the corresponding row (Read from disk),
(3) take the total column,
(4) Sum it up, and do that 466k times.
In essence, we do 466k read from disk! That’s bad.
You may ask here that
Q: “Isn’t full table scan worse since you have to read from the disk 2.6 millon times?”
A: No! The DB is smart enough. It knows that it has to do full-table scan anyway so it will not read one by one from the disk. It will batch read couple of 1000s at a time. Hence the amount of IOs will be way less. Turns out in this example, despite it has to look at 5x times more rows, the full table scan is way faster than RANGE due to capped disk IOs.
So, DB has rightly decided that Full Table Scan is faster!
Next suggestion: If not all data is in the index, why not put total column in the index as well?

Now it is choosing our index, as it doesn’t have to read from the disk anymore.
This now took 90 ms.
Take a look at Extra (Another terrible name) column: Using Index.
- What it really means is that Using index ONLY.
- We have put all the data this query needs on the index. So this operation can be entirely done in memory. (Because MYSQL stores all indices in memory) No read from disk at all!
This is index only scan. It is one of the most powerful tools when you are designing an index. But it is also one of the most aggressive ones.
- We have created a very specific index. That would probably only works for this query. Because not only we have index for WHERE clause but index for SELECT clause
- Considering the fact that we need to minimise our index to minimum we need. Introducing an index like this that only works for single query is a trade-off you must consider.
Anyway, you are now happy with the result and the manager comes to you next day.
“Great job, but we have a feature request. We want the same report but we want to do this for only single employee”
Well.. this sounds easy,
SELECT SUM(total)
FROM orders FORCE INDEX (orders_created_at_idx)
Where created_at BETWEEEN '2013-01-01 00:00:00' AND '2017-12-31 23:59:59'
AND user_id = 136;
It took 2 seconds. Arg! Let’s put explain syntax.
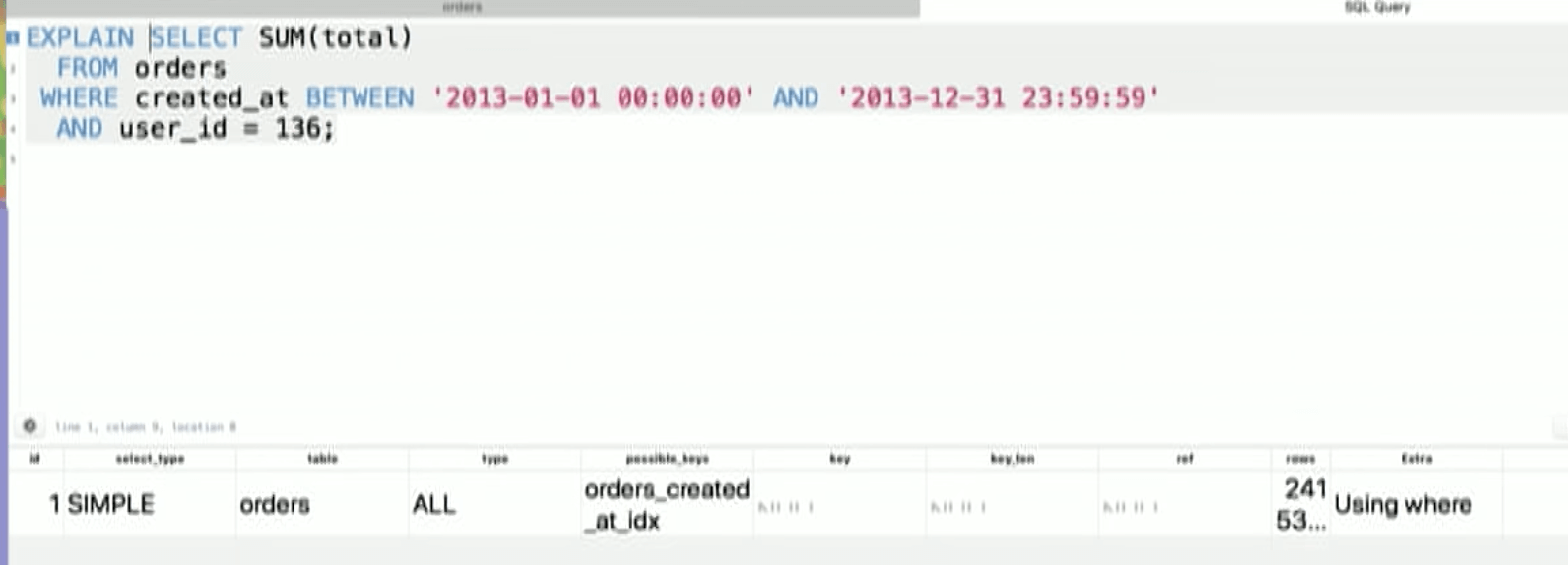
OMG we are back to full table scan again.
But this is pretty simple. Bascially we’ve introduced the same problem. We added a new column user_id that is not on the index so it has to read from the disk.
Again, let us add user_id to index.
current Index
created_at, total, user_id
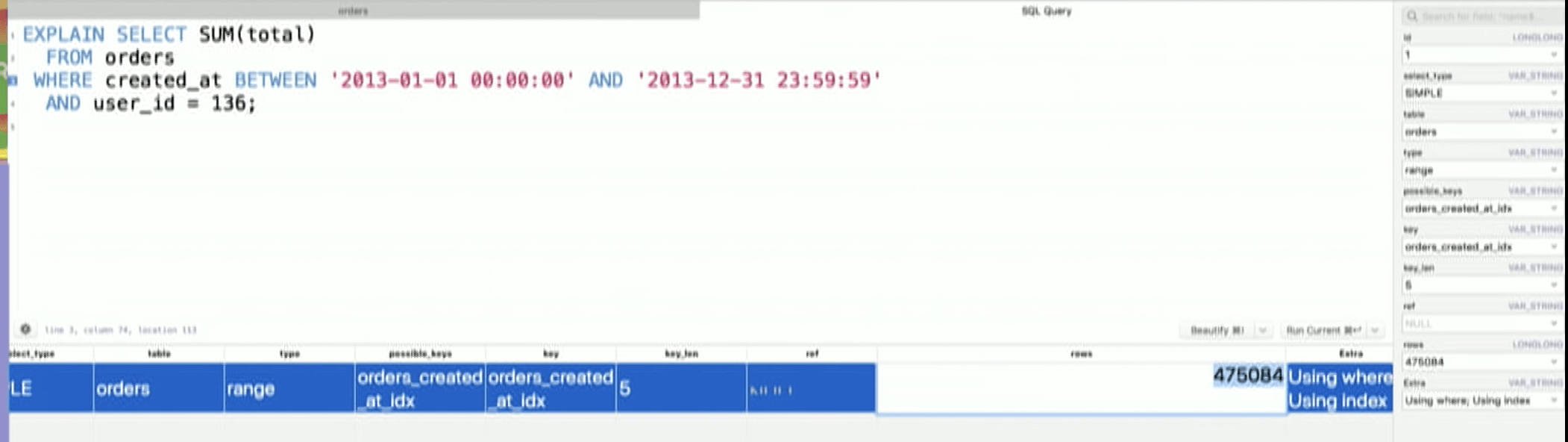
We are back to using range scan & Using index.
Something is still not right though. It still has to look at half a million rows. Exactly the same as when we didn’t have user_id constraint. Despite user_id = 136 being much more limiting constraint.
What this suggests is
- Yes it is using index but it is not using it to full extent.
3. The column order matters!
This is what our index looks like right now:
This means that the index is sorted by created_at, total, and user_id respectively.
i.e. If two rows have the same created_at value then it looks at total and then if created_at and total values are the same then looks at user_id.
Multi-column indices.
- Left to right
- For this multi-column indices you can have the following indices.
- created_at
- created_at, total
- created_at, total, user_id
- Notice you cannot skip the columns! (No created at, user_id)
Back to our query we have WHERE clause at created at and user_id. We are skipping the total. This doesn’t work. Why doesn’t it work? Because the user_id is not sorted. It is only sorted in respect to total and then created_at. So if we leave out the middle, user_id column is essentially unsorted.
Therefore in this query. We are only using indices up until created_at.
Column order matters:
index(a, b) ≠ index(b,a)
So let us swap the indicies
index:
created_at, total, user_id → created_at, user_id, total
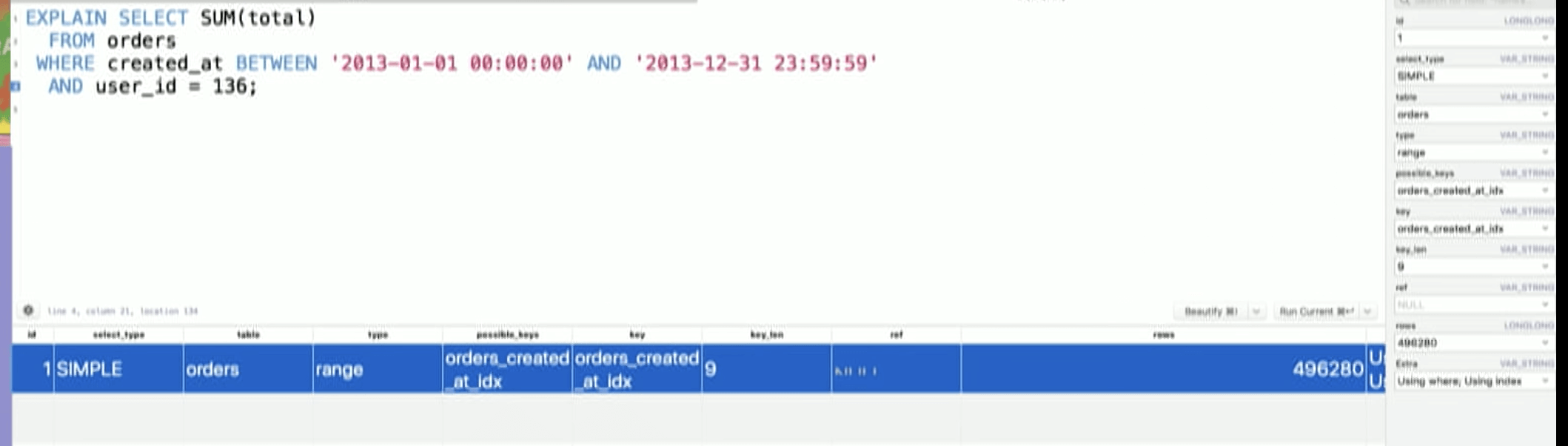
However, when we run the query, it still looks at the similar number of the rows.
Note: actually, we have slightly more rows to look at compared to the previous but this is due to “estimation”.
4. Inequality operators.
Yes, you can use index left to right, but as soon as have an inequality operators on any of these columns in the index, the index stops there.
We have inequality operator ‘BETWEEN’ on the created_at column.
created_at is the first column in our index so our index stops at created_at.
index:
created_at, user_id, total → user_id, created_at, total
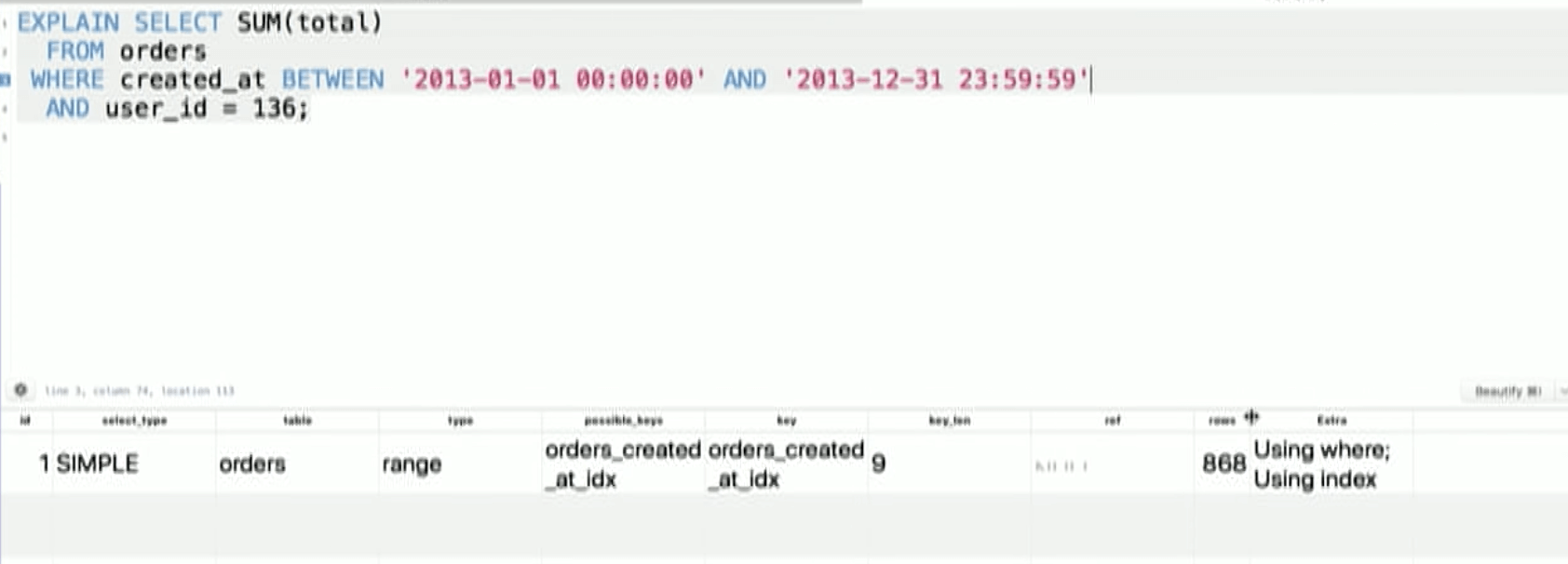
Now it is using the index to full extent.
It took < 1ms.
4 seconds to 1 ms.
Next day, manager says
“This new query works really well but but the report on all orders are slow again”
EXPLAIN SELECT SUM(total)
FROM orders FORCE INDEX (orders_created_at_idx)
Where created_at BETWEEEN '2013-01-01 00:00:00' AND '2017-12-31 23:59:59'
We are back to 600ms.
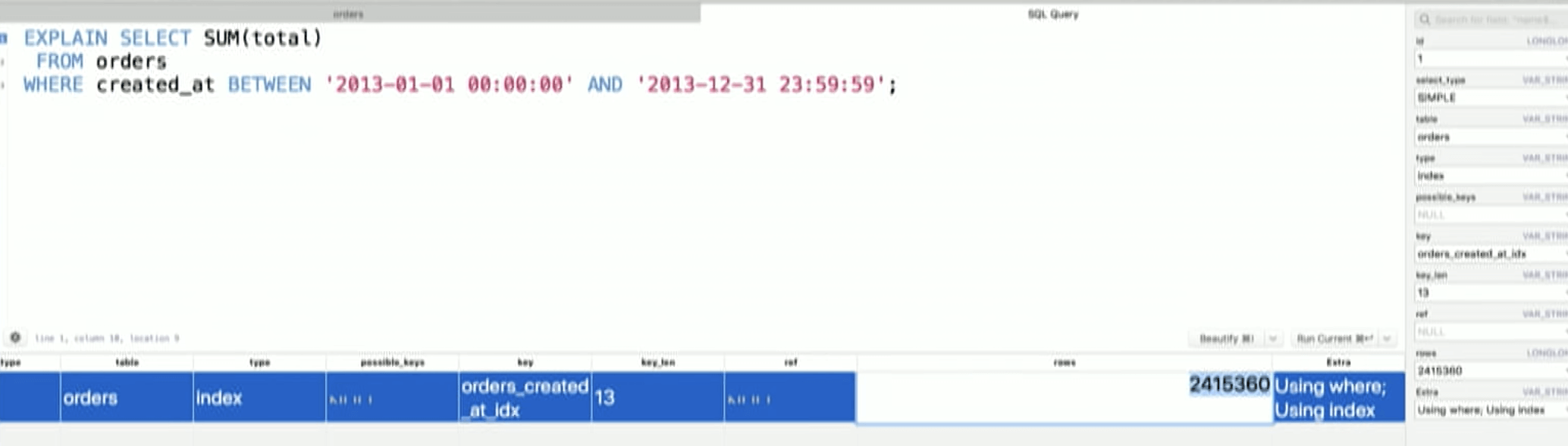
INDEX. We are now doing a full index scan.
We are using index but we are not limiting the rows we need to look at. We start from the first leaf node, traverse 2.5 million rows to the very last node.
What happend?
We changed the order of the index and the query doesn’t have user_id.
Because our index is user_id, created_at, total and we cannot skip columns, we can’t use index anymore.
Lesson to take away:
- There is no index that can satisfy both of these queries. Indexing is a developer concern. NOT a concern for a database personell doing MYSQL workbench all the time.
-
You do not design index in a vacuum. You design it for a query. Only devs are in a position to write a good index.
So it is YOUR JOB to decide “Do I need 2nd index? Is report for all users simply run once per year? In that case speed doesn’t matter if it takes 600ms.”
You can only decide this if you know the context of how your database will be accessed.
){kind=link}