Django 1.11.14 기준 - 발표내용에서 나온 내용은 12.0에 문제 없이 적용가능하다.
위 발표에서 만들어본 문제는 다음과 같다. 아래 대부분의 질문을 답할 수 있다면 이 글을 읽어볼 필요는 없다.
Active-Recall questions
- 운영팀에서 정산 버튼을 실수로 두번 눌러서 되돌려 달라고 한다. Django ORM의 어떤 기능을 사용하면 이를 효과적으로 rollback할 수 있을까?
- created_at, updated_at 필드를 모든 models에게 넣어주고 싶다. 추상화를 이용해서 중복된 코드를 줄이려면 어떻게 구현해야 할까?
- 아래 사진에서 많은 카운트로 인해 속도가 늦는다. 해결 방안은?

- Django에서 enum 쓰려면 어떻게 해야할까?
def get_investment(user_id):
result = []
investments = investment.objects.filter(user_id=user_id)
for investment in investments:
element = {
'investment_amount': investment.amount
'loan_title': investment.loan.title
}
result.append(element)
-
위 코드의 문제점과 해결법은?
- 추상화를 이용해서 자주 발생하는 filter (ex. status completed, not completed) 를 매니저를 이용해 pre-defined 하게 만들어보자
- Transactions.atomic의 using은 리스트를 지원하지 않는데 두가지 이상의 데이터베이스를 엮어서 lock을 걸때 사용할 수 있는 workaround는?
@transaction.atomic
def invest(loan_id, user_id, amount):
a = AnotherModel.objects.all().first()
loan = Loan.objects.select_for_update().get(pk=loan_id)
balance = Balance.objects.select_for_update().get(user_id=user_id)
- 위 코드의 문제점은?
- Transaction사용시 breakpoint 때 데이터베이스 결과가 보이지 않는다. 보이지 않는 이유는 무엇이며 어떻게 확인할 수 있을까?
- Prefetch_related 와 Search_related의 주요 차이점은?
- 내부적으로는 여러 status가 있지만 고객에게는 단순화된 status를 추상화와 case, when을 사용하여 보여주고 싶다. 어떻게 할까?
- (위 질문과 연계됨) 기획팀에서 status 순서가 반드시 Completed, planned, delayed, long_overdue, sold로 고객에게 보여주어야한다고 말한다. 어떻게 할 수 있을까?
- Django ORM 에서는 abs sum 을 제공하지 않는다. 커스텀 펑션으로 만들어보자.
1. Update_or_create
django.db.models.QuerySet.update_or_create()
역등성을 보장하는 함수 update_or_create 없으면 만들고 있으면 수정 → Idempotent.
운영팀에서 불의의 실수가 있어서 정산 버튼을 두번 눌러도 복구가 가능하다.
def settle(loan_id, sequence, amount):
settlement, created = \
settlement.objects.update_or_create(
loan_id=loan_id, sequence=sequence,
defaults={'amount':amount}
if created:
return 'Settlement completed!'
return 'you have already settled this!'
2. Overriding predefined model methods
django.db.Model.save()
피플펀드에선 후킹 요소로서 해당 채권에 몇 명이 투자했는지 보여준다. 문제는 각 채권마다 투자자들을 항상 카운트 해주어야해서 오버헤드가 크다.

역정규화와 save를 override함으로써 이를 해결했다.
class Investment(models.Model):
def save(self, *args, **kwards):
self.loan.investor_count += 1
self.loan.save()
super().save(*args, **kwargs)
투자할 때 loan의 investor_count 를 1을 올려준다.
리스트를 가져올 때 각 채권마다의 카운트가 아니라 채권정보만 가져오면 필요한 정보가 이미 있다.
class Investment(models.Model):
def save(self, *args, **kwards):
self.loan.investor_count += 1
self.loan.save(update_fields=['investor_count', 'updated_at')
super().save(*args, **kwargs)
save()는 기본적으로 할당된 모든 값을 저장하나 이것도 overhead기 때문에 한두개 필드만 업데이트 할 경우 update_fields를 사용하는 것이 좋다.
- 하지만 update_fields를 사용하면 auto_now attribute가 동작하지 않기 때문에 updated_at도 함께 업데이트해야한다..
3. Enumerations
model_utils.Choices
Enum은 Python 3.4부터 지원되는대도 불구하고 Django에서는 단순한 문자열이다.
‘django-model-utils’ 패키지:

Enum처럼 활용 가능하다.

1을 변수명으로 쓰고 싶지만 파이썬은 숫자를 변수명으로 사용할 수 없다. 그런데 (1, ‘Code1’, 1) 이런식으로 값과 실제로 쓰는 코드를 분리해서 사용할 수 있다.
4. Abstract models
대표님들이 특정 거래의 정확한 시간을 알고 싶어하실 때가 있다. 그런데 1년 이상 뒤에 물어보는 경우가 많다! → created_at, updated_at 필드를 모든 models에게 넣어주었다.
→ 공통된 속성이 모든 모델에 다 들어가서 당연히 추상화를 해주는 것이 좋다.
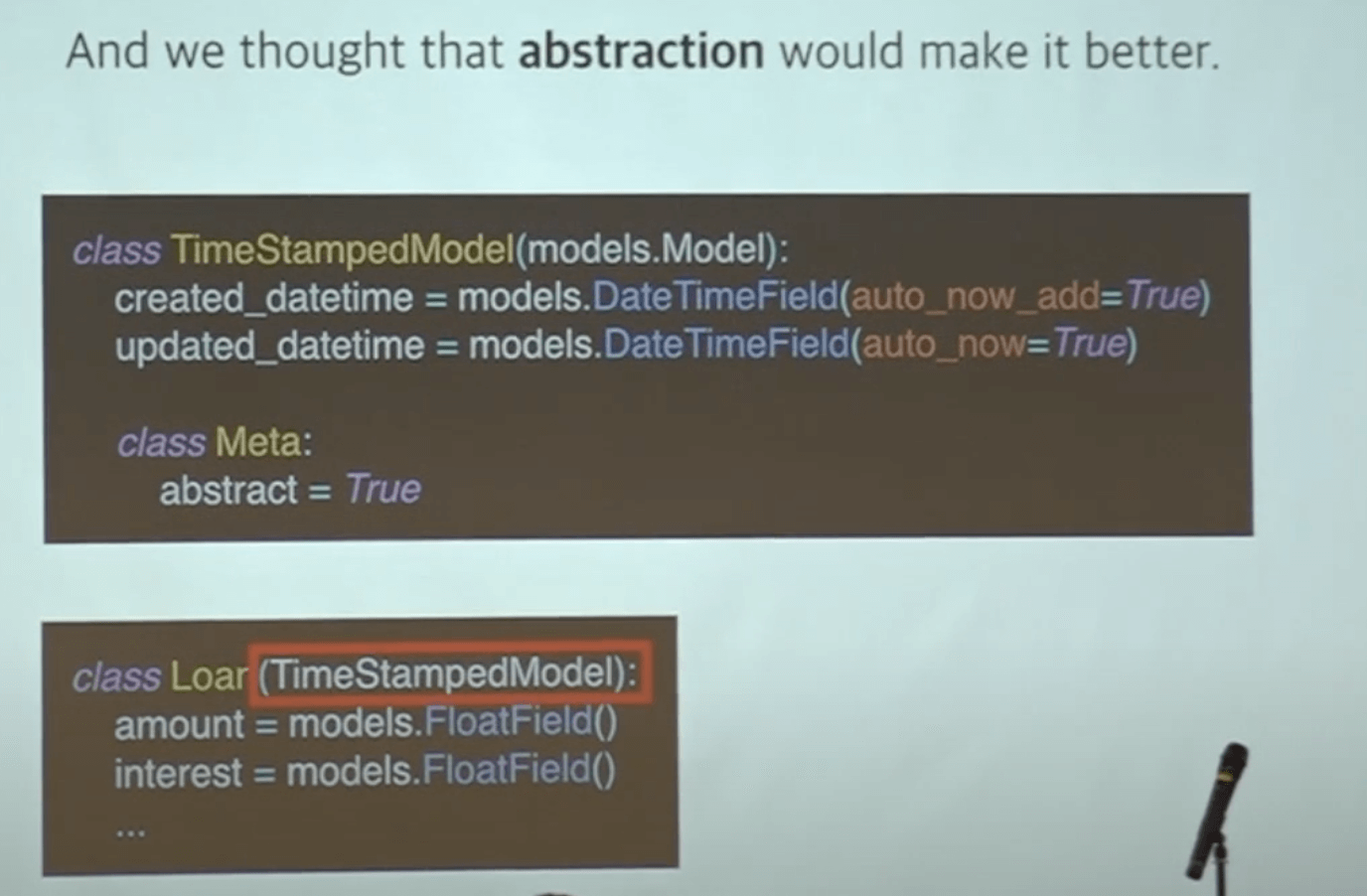
class Meta: abstract = True 로 추상화를 만든다. 실제로 데이터베이스에 반영되지 않는다.
Loan은 타임스탬프모델을 상속을 받고 created_at, updated_at 은 당연히 가져가게 된다.

담보 채권, 개인 신용 채권. 속성이 굉장히 비슷한 부분이 많다.
개인 신용 - 특정 사람의 신용 점수, 담보 채권 - 담보 ID.
5. More abstract.
대표님이 raw data도 보고 싶어하신다. And the team became annoyed with it..

다른 사람들이 이름에 인식하게 하기 더 쉽게 하기 위해 verbose_name을 붙였다.
Find a field name by ‘verbose_name’
def get_field_name_by_verbose_name(verbose_name, model):
for field in model._meta.fields:
if field.verboose_name == verbose_name:
return field.attname
return None
Verbose_name과 이름을 입력하면 해당 유저 raw_data가 엑셀로 생성


추가로 이메일도 파라미터화 하여 바로 이메일로 쏴줄수 있게 하였다 ㅋㅋㅋ!
추상화를 넓게 해석해서 적용한 케이스.
Managers
django.db.models.manager.Manager*
6. Predefined filters
이번달에 이 채권에서 얼마의 이자를 내야해요? → Calculation based on remaining principal
오늘부터 이 채권에서 얼마정도의 돈을 벌 수있어요? → Summation based on remaining interest
이 채권의 원금이 얼마정도 남아있는 것이에요? → Summation based on remaining principal
남아있는 것이 무엇인가를 찾아야하는 과제!
과거에는 3가지 기능을 따로 구현했었으나 추상화를 이용해서 공통적인 요소를 줄일 수 있었다.
# 완료된 상태 필터
.filter(
loan=loan
status_in=REPAYMENT_STATUS.COMPLETED
)
# 완료되지 않은 상태 필터
.filter(
loan=loan
).exclude(
status_in=REPAYMENT_STATUS.COMPLETED
)
ORM 사용 시 Model.object.filter 같은 함수를 자주 사용하게 되는데 이때 사용하는 object를 Manager라고 하는데 매니저를 활용하면 위 필터를 다음과 같이 바꿀 수 있다.
Manager를 custom define해서 사용하는 방법을 알아보자.
class RepaymentManager(models.Manager):
def completed(self, loan):
return self.filter(
loan=loan,
status_in=REPAYMENT_STATUS.COMPLETED
)
def not_completed(self, loan):
return self.filter(
loan=loan
).exclude(
status_in=REPAYMENT_STATUS.COMPLETED
)
.
.
.
class Replayment(models.Model):
objects = RepaymentManager()
상환 RepaymentManager 모델은 django에서 제공해주는 models.Manager 상속을 받고
Completed와 Not completed 두가지 메서드를 정의해놓으면 다음과 같이 사용이 가능하다.
...
remaining_principal = Repayment.objects.not_completed(
loan=loan
).aggregate(
remaining_principal=coalesce(Sum('principal'), 0)
)['remaining_principal']
...
채권 정보만 넘겨부면 미리 정의된 쿼리셋이 나온다.
물론 쿼리셋이기 때문에 연결해서 함수를 엮어서 사용 가능하다.
Aggregation & Annotation
7. Group by
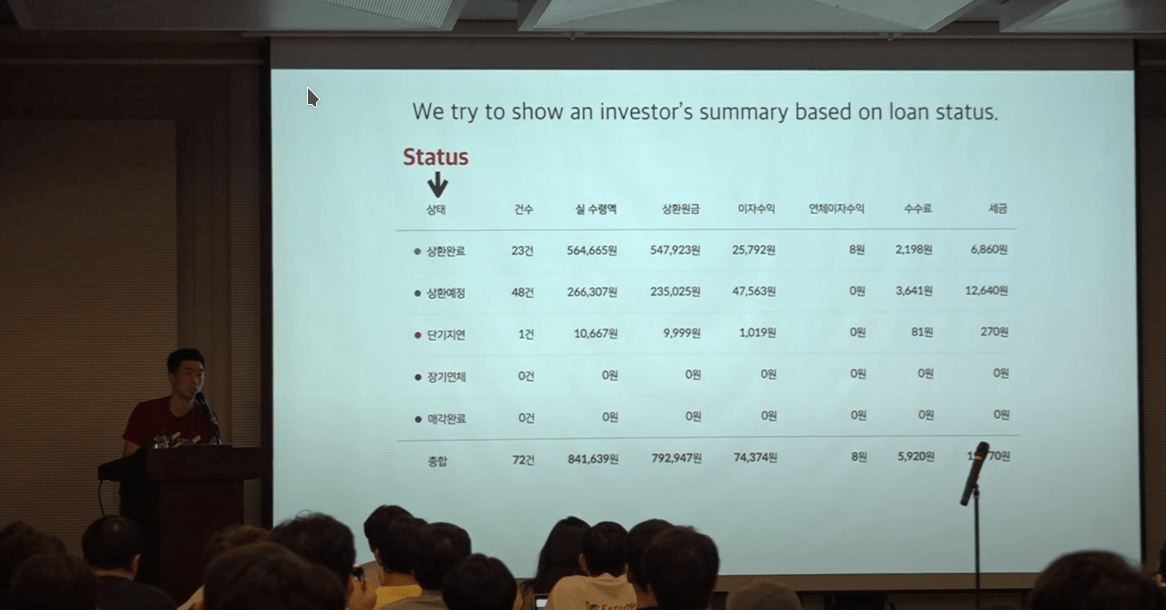
채권을 100개 이상 투자시 한개씩 보기 어려우니 Summary 를 보여주고 싶었다.
Summary는 상환이 예정되어있는 데이터의 상태를 기준으로 하기 때문에 Group by로 묶었다.
우선 어떤 투자자와 기간을 언제인지 필터를 건다.
schedules = Schedule.objects.filter(
user_id=user_id,
planned_date_gte=start_date,
planned_date_lt=enddate
)
이후 values 라는 키워드를 사용한다. Django에서는 values라는 뜻이 중의적으로 사용되고 있다. 보통 values라고 하면 해당 모델의 특정 필드의 값을 가르키는데 annotate나 aggregate 이런 함수 앞에 쓰이게 되면 group by로 동작하게 된다.
schedules = schedules.values('status').annotate(
cnt=Count('loan_id', distinct=True),
sum_principal=AbsoluteSum('principal'),
sum_interest=Sum('interest'),
sum_commission=Sum('commision'),
sum_tax=Sum('tax')
)
이 코드를 실행하면 aggregate된 값을 볼 수 있다.

8. Conditional Aggregation
조건이 들어가는 집계를 만들어보자.

여러 상태의 데이터가 있다.
- 상환 예정 → 돈을 값는다 → 상환 완료
- 정산을 해주는 중이면 정산중이다.
- 연체도 단기 연체, 단기 지연이 있다.
실제로는 더 많은 상태가 있으나 기획파트에서는 모든 상태를 다 보여주기 보다는 간략한 정보를 보여주고 싶어했다.
그러기에 좀 더 추상화된 상태값이 필요했다. 여러 방법이 있겠지만 Case, When 문을 적용해보았다.
custom_status_annotation = Case(
When(status_in=(PLANNED, SETTLING), then=Value(PLANNED)),
When(status_in=(DELAYED, OVERDUE), then=Value(DELAYED)),
When(status_in=(LONG_OVERDUE), then=Value(LONG_OVERDUE)),
When(status_in=(SOLD), then=Value(SOLD)),
default=Value(COMPLETED),
output_field=CharField(),
)
예) 위 코드를 보면 상태가 상환중이거나, 정산중일때 항상 상환 예정으로 보이게 만들었다.
이런식으로 미리 정의를 해두면 케이스문을 다음과 같이 annotate에 활용 가능하다.
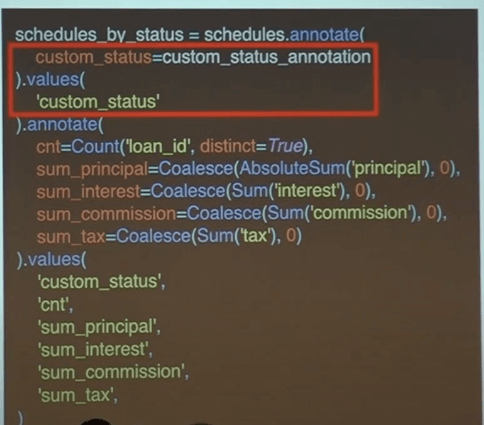
하지만 이것이 끝은 아니었다. 내부 클라이언트는 기획에서 보여준 순서 그대로 표기하는 것이 중요하다고 하였다.
custom_status_annotation = Case(
When(status_in=(PLANNED, SETTLING), then=Value('02_PLANNED')),
When(status_in=(DELAYED, OVERDUE), then=Value('03_DELAYED')),
When(status_in=(LONG_OVERDUE), then=Value('04_LONG_OVERDUE')),
When(status_in=(SOLD), then=Value('05_SOLD')),
default=Value('01_COMPLETED'),
output_field=CharField(),
)
간단하게 숫자를 앞에 붙이고 order_by를 추가했다.


이렇게 추상화 되어있는 카테고리를 통해 순서가 보장된 집계를 하여 문제를 해결했다.
9. Custom Functions (AbsoluteSum*)
ORM에서 제공하는 함수로는 한계가 있다. 이 부분은 RDMS 구현하는 회사마다 다른 부분이 존재하기에 어쩔 수 없다.
피플펀드 사례: 전체 거래 총합 구하기 (절대값)

피플펀드에서는 transaction을 단순한 방법으로 처리를 했다.
- 돈이 들어왔을 때 양수로 입력을 하고,
- 돈이 나가면 음수로 한다.
이 방식은 잔고를 단순히 sum을 하면 계산이 되는 장점이 있었다.
내부 클라이언트가 실제 거래가 된 금액의 총합 (절대값)을 구해달라고 요구했다.
그러나 Django ORM 에서는 sum은 제공하지만 abs sum 은 제공하지 않았다.
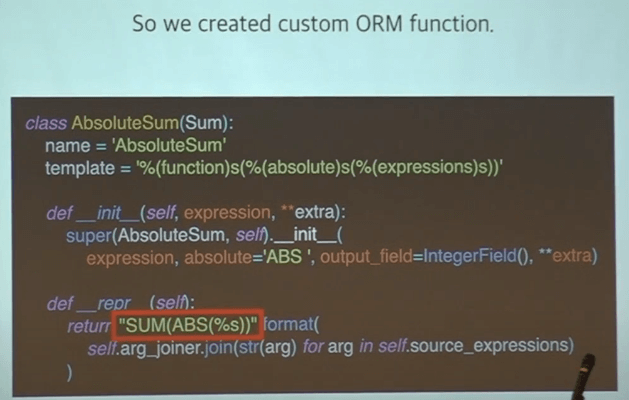
Sum 기본적인 함수를 상속받고 대부분은 그대로 나두었고 빨간 박스 안에 보이듯이 단순히 SUM 안에 ABS 를 적용시켜주었다.

Transactions
10. Locks
QuerySet.select_for_update
피플펀드는 금융서비스 회사이다 보니 transaction 또는 lock을 많이 사용하게 된다.
사례:
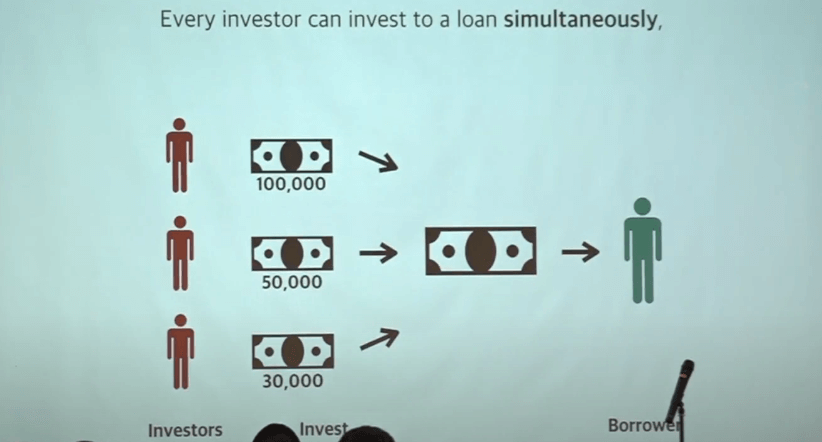
투자자가 투자를 하여 대출자가 돈을 빌려간다. 문제는 투자를 할 때 여러명이 동시에 투자를 하게 될 수 있다. 가령 대출자는 원래 15만원을 빌려가기로 했다. 그런대 투자자가 위 그림처럼 해당 금액을 넘겨서 동시에 투자를 하게 될 때 매치가 안되면 투자가 되지 않는 금액이 통장에서 빠져나갈 수 있다.
이것을 해결하려면 Lock을 사용할 수 밖에 없다:
@transaction.atomic
def invest(loan_id, user_id, amount):
loan = Loan.objects.select_for_update().get(pk=loan_id)
balance = Balance.objects.select_for_update().get(user_id=user_id)
# time.sleep(60) 테스트용..
transcation.atomic이 있어서 적용하고 싶은 로직 맨 앞에 적용을 할 수 있고,
RDMS에는 select_for_update라는 함수를 제공하고, 특정 row들 select시 다른 프로세스에서 접근 시도시 commit 이 완료하기 전까지 기다려야하기 때문에 isolation이 보장된다.
이 둘을 통해 투자자들의 순서를 atomic하게 보장해줄 수 있는 방법을 사용했다.
그러나 하나의 문제가 있었다.. transaction을 걸고 lock도 걸었지만 이 것을 어떻게 100퍼센트 보장하는 테스트 케이스를 짜지??
피플펀드에서는 단순히 time.sleep(60) 넣고, 개발자 여러명이 동시에 요청을 하여 눈으로 이상 없는지 테스트를 했다… 아직 테스트 코드로 백퍼센트 커버할 수 있는 좋은 방법이 떠오르지 않는다.
한가지 팁: Lock을 사용시 순서가 굉장히 중요하다:
@transaction.atomic
def invest(loan_id, user_id, amount):
a = AnotherModel.objects.all().first()
loan = Loan.objects.select_for_update().get(pk=loan_id)
balance = Balance.objects.select_for_update().get(user_id=user_id)
Transaction을 시작을 했으나 내가 lock을 걸려고 했던 모델에 접근하기 전에 다른 모델에 접근을 하게 된다면 (Lock을 사용하지 않는 쿼리가 실행) lock을 얻어올수가 없다!
크리티컬한 문제다: 항상 락을 사용한다면 트랜젝션을 실행하고 나서 가장 먼저 실행되는 쿼리가 락을 획득하는 쿼리가 실행이 되어야한다는 점을 유의해야만 한다.
11. Locks with two or more DBs
데이터베이스가 여러개인데 한꺼번에 transaction과 lock을 걸어야하는 문제가 있었다.
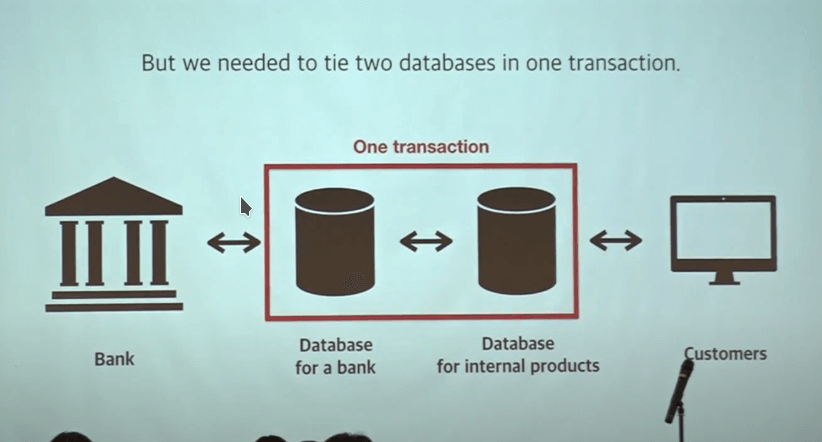
돈을 다루는 만큼 은행과 통신을 해야한다. 피플펀드에는 은행과 통신하는 데이터베이스가 따로 있고 내부 피플펀드 서비스용을 위한 데이터베이스가 따로 있다.
이 엮는 방법을 안타깝게도 공식적으로 Django에서는 지원을 해주고 있지 않다.
대신 이런 우회 방법이 있다.
with transaction.atomic(using='default'):
with transaction.atomic(using='bank'):
peoplefund = PeoplefundModel.objects.select_for_update().get(pk=loan_id)
bank = BankModel.objects.select_for_update().get(user_id=user_id)
...
아까 트랜젝션을 활용할 때 annotation을 사용을 했지만 여기서는 with 구문으로 같이 사용을 했다.
transaction.atomic에 있는 using이라는 attribute은 공식적으로 리스트를 지원하지 않는다.
따라서 중첩해서 활용하게 되었다.
Performance
12. Join
prefetch_related & select_related
Django ORM에서는 join할 때 성능문제가 자주 발생하게 된다.

투자자별로 투자 채권 현황을 볼때 두가지 다른 모델에서 데이터를 가져오기 때문에 두번 조회를 해야한다.
처음 만든 코드는 이런 형식이었다:
def get_investment(user_id):
result = []
investments = investment.objects.filter(user_id=user_id)
for investment in investments:
element = {
'investment_amount': investment.amount
'loan_title': investment.loan.title
}
result.append(element)
문제점은 Django ORM은 investment.amount 를 최초로 접근할 때 쿼리셋에 있는 있는 모든 리스트를 한번에 가져온다.
그런데 쿼리셋을 순회를 하면서 쿼리셋 모델에 하나에 연결되어있는 데이터를 가져올 때는 연결된 데이터를 한번 접근할때마다 쿼리를 날린다. 당연히 리스트를 가져올 때 n번 실행이 더 되는 무시무시한 결과가 나온다!
해결 방법: select_related
def get_investment(user_id):
result = []
investments = investment.objects.select_related('loan').filter(user_id=user_id)
for investment in investments:
element = {
'investment_amount': investment.amount
'loan_title': investment.loan.title
}
result.append(element)
기본 쿼리셋은 investment 모델을 기준으로 하지만 loan을 접근 할때도 새롭게 쿼리를 실행을 하는 것이 아니라 처음에 리스트를 가져올 때 loan까지 조인해서 가져오게 된다.
Q. Prefetch_related 차이?
select_related는 1:1 모델에서 사용하고 prefetch_related는 many:many 나 1:many
Debugging
13. Checking REAL queries
django-debug-toolbar
쿼리가 느릴 때 쿼리를 어떻게 만드는지 확인해야 할 필요가 있다.
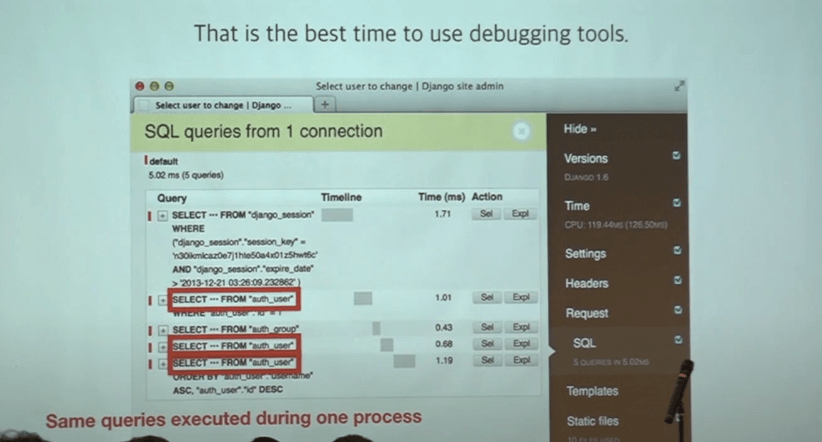
프로세스에서 실행되었던 모든 쿼리를 출력하는 기능이 있다.
위의 경우 이미 실행된 커리를 n번 부르고 있는 것을 확인 가능하다.
14. Watch data at a breakpoint in a transaction
isolation level*
transaction과 lock을 사용 시 debug에 어려운 문제가 있다. breakpoint 이전과 이후 결과 값이 의도대로 실제로 흘러가는지 보고 싶다: (아래 사진은 transaction으로 묶여있다고 가정)

이 코드대로라면 순차적으로 investment를 돌면서 데이터가 하나씩 바뀌어야한다. 그런데 breakpoint에 도착한 상태로 데이터베이스 조회를 하면 아무 결과도 안보인다.
transaction내 결과물은 실제로 커밋이 되기 전까지는 데이터베이스에 반영이 안되기 때문이다.
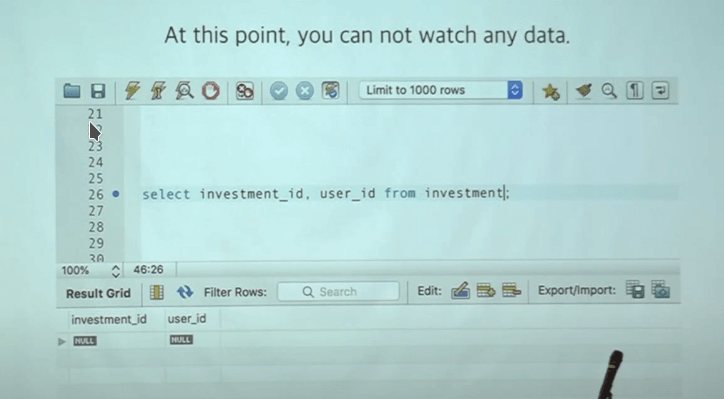
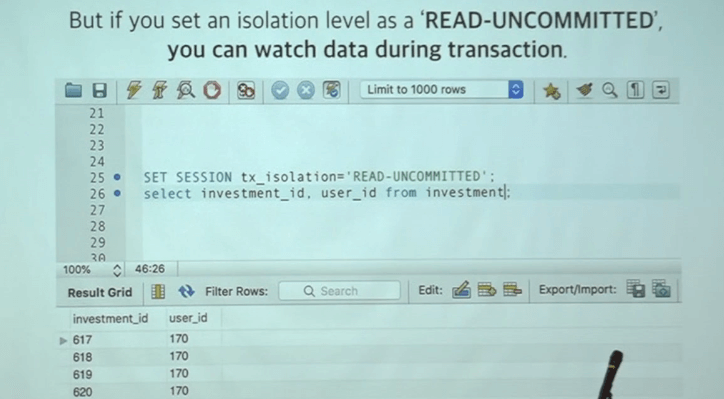
그런데 사실 데이터베이는 알고는 있어서 isolation level 을 ‘READ_UNCOMMITED’로 정하면 트랜젝션 도중에도 캐쉬된 이 데이터를 볼 수 있다!
){kind=link}